
Technology-Enabled Marketing Decision-Making
-
Methods on Leveraging LLMs for Enhanced Decision-Making
1.LLM-Driven Causal Discovery and Inference: A Multi-Agent Bayesian Framework
-
Chen Wang (HKU), Shan Huang* (HKU), Shichao Han (Tencent) and Yong Wang* (Tencent)
-
Presented at MIT CODE 2025
Understanding why treatments work differently across heterogeneous user groups is critical for reliable causal inference about future interventions and for autonomous decision-making. We explore how large language models (LLMs) can help uncover group-specific causal mechanisms from historical A/B tests and leverage them to improve downstream causal inference. We propose a multi-agent Bayesian framework powered by LLMs. The framework first identifies user subgroups that exhibit heterogeneous treatment effects. An LLM-based reasoning agent then hypothesizes potential causal factors that may explain the treatment effects within each subgroup. A feedback agent subsequently evaluates these hypotheses using the data and performs Bayesian inference, dynamically updating their posterior probabilities as new experimental evidence becomes available. This closed-loop process enables the system to continually refine its understanding of the underlying causal structure while improving treatment-effect estimation and prediction for new interventions at both the subgroup and population levels. We validate the framework by evaluating both the effectiveness of the identified causal factors and its ability to conduct causal inference for new treatments using large-scale real-world experiments from the WeChat platform.
2. LLMs in Product Selection for Small E-Commerce
-
Yi Ji (HKU) & Shan Huang*(HKU)
Product selection is a persistent challenge for small businesses. With limited data and technical expertise, these firms often rely on intuition rather than evidence. Recent advances in large language models (LLMs) offer a promising alternative for supporting data-driven decisions in resource-constrained settings. We propose an LLM-based product selection framework that emphasizes comparative rather than single-item prediction. Using the data from a representative small ecommerce and Google Ads, we show that LLMs perform poorly without contextual references, but that constructing reference groups and enabling comparative reasoning substantially improves predictive accuracy. However, larger reference groups reduce performance, and different grouping strategies lead to meaningfully different outcomes. Our approach significantly outperforms competitive machine learning models in predicting product-selection outcomes. These findings provide practical guidance for small businesses making product decisions and offer new insights into how LLMs leverage relational information in decision-making tasks.
-
Methods for Aligning Short-Term Experiments With Long-Term Decisions in Online Experiments (A/B tests)
1. Estimating Effects of Long-Term Treatments
-
Shan Huang*(HKU), Chen Wang(HKU), Yuan Yuan (UC Davis), Jinglong Zhao (Boston University) & Jingjing Zhang (Tencent)
-
Management Science, forthcoming
-
Early version accepted by ACM EC'23
Estimating the effects of long-term treatments in A/B testing presents a significant challenge. Such treatments - including updates to product functions, user interface designs, and recommendation algorithms - are intended to remain in the system for a long period after their launches. On the other hand, given the constraints of conducting long-term experiments, practitioners often rely on short-term experimental results to make product launch decisions. It remains an open question how to accurately estimate the effects of long-term treatments using short-term experimental data. To address this question, we introduce a longitudinal surrogate framework. We show that, under standard assumptions, the effects of long-term treatments can be decomposed into a series of functions, which depend on the user attributes, the short-term intermediate metrics, and the treatment assignments. We describe the identification assumptions, the estimation strategies, and the inference technique under this framework. Empirically, we show that our approach outperforms existing solutions by leveraging two real-world experiments, each involving millions of users on WeChat, one of the world's largest social networking platforms.

2. Enhancing External Validity of Experiments with Ongoing Sampling
-
Chen Wang (HKU), Shan Huang*(HKU), & Shichao Han (Tencent)
-
Early version accepted by ACM EC'24
Subjects in online experiments typically arrive and participate sequentially, which can compromise the external validity of experimental results and downstream decision making due to temporal shifts in sample characteristics. This issue is especially pronounced in short-duration experiments such as A/B tests. To address this challenge, we introduce a novel framework that adapts to the dynamic nature of participant arrival to improve external validity in online experimentation. Our method segments the sampling process into three distinct stages—unstable, overlapping, and representative—each corresponding to different levels of generalizability. Leveraging survival analysis, we develop a heuristic function that detects these stages in real time and enables the construction of stage-specific estimators for the average treatment effect. We evaluate our framework using both a real-world A/B test and a platform-scale application involving 600 experiments conducted on WeChat, a major social media platform. The approach improves true positive decision rates by 28–37% while reducing false positive rates by 17–29%. We further provide practical implementation guidelines for practitioners. This framework has since been widely adopted in Tencent’s daily A/B testing operations.

Technology-Enabled Marketing Strategy
-
Empirical Evidence on New Digital Strategies in Social Media Platforms Using Large-scale Online Experiments and Computational Methods.
1. Social Advertising Effectiveness: Evidence from A Large-scale Field Experiment
-
Shan Huang*(UW), Sinan Aral (MIT), Yu Hu (Georgia Tech) & Erik Brynjolfsson (MIT).
-
Published in Marketing Science
Most of the empirical evidence on social advertising effectiveness focuses on a single product at a time. As a result, little is known about how the effectiveness of social advertising varies across product categories or product characteristics. We, therefore, collaborated with a large online social network to conduct a randomized field experiment measuring social ads effectiveness across 71 products in 25 categories among more than 37 million users. We found some product categories, like clothing, cars and food exhibited significantly stronger social advertising effectiveness than other categories like financial services, electrical appliances, and mobile games. More generally, we found that status goods, which rely on status-driven consumption, displayed strong social advertising effectiveness. Meanwhile, social ads for experience goods, which rely on informational social influence, did not perform any better or worse than their theoretical counterpart search goods. Social advertising effectiveness also significantly varied across the relative characteristics of ad viewers and their friends shown in ads. Understanding the heterogeneous effects of social advertising across products can help marketers differentiate their social advertising strategies and lead researchers to more nuanced theories of social influence in product evaluation.
2. Do More "Likes" Lead to More Clicks? Evidence from a Field Experiment on Social Advertising
-
Shan Huang (HKU)* & Song Lin (HKUST)
-
Published in Journal of Marketing
One unique feature of social advertising is the coexistence of public and private consumer responses. Social media allows users’ certain responses (e.g., likes) to be publicly revealed to one's social network. More importantly, public responses can also influence private responses (e.g., clicks). We, therefore, use data from a large-scale field experiment with a major social media platform (WeChat Moments) to investigate how the display of social cues (friends' likes) affects users' public (likes) and private responses (clicks) to social ads. We find that, on average, displaying the first social cue significantly enhances the liking rate and the clickthrough rate. Nevertheless, although showing additional social cues can further increase users' tendency to like an ad, it does not further increase the clickthrough rate. This empirical pattern is consistent with the interplay between informational and normative social influence in social advertising. Overall, we find that the coexistence of the two forces can enhance the conformity effect on the public liking response. However, when normative social influence dominates, a crowding-out effect on the private clicking response may occur. Our results have rich implications for advertisers and social media platforms in regard to the design of social advertising policies and social networks.
3. Emotions in Online Content Diffusion
-
Yifan Yu (UT Austin), Shan Huang*(HKU), Yuchen Liu (UF), & Yong Tan (UW)
-
Published in Information Systems Research
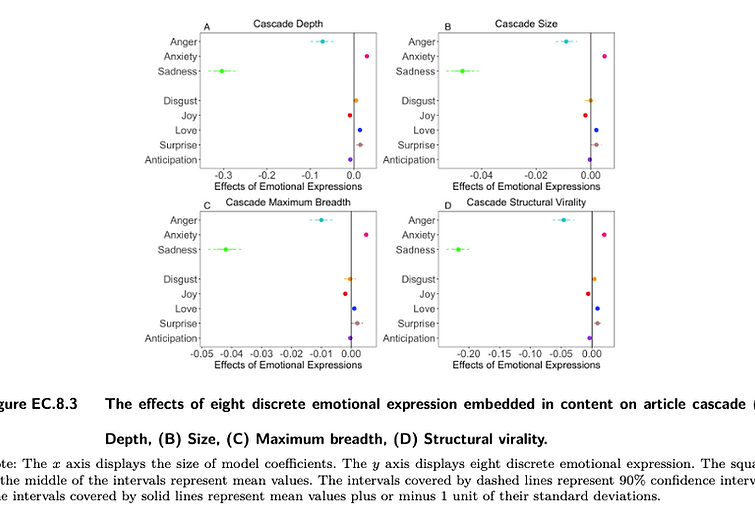
This study examines how emotional expression, specifically discrete emotional expression (i.e., expressions of anxiety, sadness, anger, disgust, love, joy, surprise, and anticipation), lead to differential diffusion of online content in social media networks. We conducted an analysis on a random sample of 387,486 online articles and their corresponding diffusion cascades, involving over six million unique individuals, on a large-scale online social network, WeChat. Discrete emotional expressions in these articles were identified using a newly generated, domain-specific, and up-to-date emotion lexicon. Our investigation focused on the structural properties of diffusion cascades (such as size, depth, maximum breadth, and structural virality), as well as individual characteristics (including age, gender, and network degree) and social ties (both strong and weak) involved in the cascading process. We employed various econometric model specifications to robustly demonstrate the relationships between discrete emotional expressions and the diffusion of online articles. Our findings reveal that articles expressing more anxiety, love, and surprise reach a larger number of individuals and diffuse more deeply, broadly, and virally. In contrast, expressions of anger, sadness, and joy exhibit the opposite effect. Expressions of disgust are associated with greater viral diffusion, while expressions of anticipation are associated with reduced levels of depth and virality. Additionally, we find that articles with different emotional expressions tend to spread differently based on individual characteristics and social ties. These findings provide valuable insights into the diffusion and regulation of online content from the perspectives of emotional expressions and social networks.
4. Algorithmic vs. Friend-based Recommendations in Shaping Novel Content Engagement
-
Shan Huang*(HKU) , Yi Ji (HKU) & Leyu Lin (Tencent)
-
Early version accepted by ACM EC'24
This study identifies the differential impact of algorithmic and friend-based recommendations—the two predominant mechanisms of online content recommendation—on users' engagement with novel information, characterized as diverse and non-redundant. Our analysis focuses on the influence of different content recommended by algorithms versus friends and the role of social influence, specifically the impact of social cues inherent in friend-based recommendations. We designed and conducted a large-scale field experiment on a major social media platform. Participants were randomly assigned to one of three groups: a control group that received content recommended by algorithms, a treatment group that viewed content shared by friends with visible social cues (e.g., friends' ``likes''), and another treatment group that was exposed to friend-shared content with the social cues hidden. The findings reveal a general preference for less novel content across all groups. However, the presence of social cues significantly mitigated this trend, indicating that social influence can encourage engagement with more novel information. Despite algorithms tending to recommend content of lower novelty, users engage more with novel content when recommended by algorithms than by friends with and without social cues. The study also discovered significant variations in engagement with novel content among users of different genders, ages, and city tiers. These results carry important implications for the design of content recommendation systems and inform policymaking regarding the dissemination of information online.